While the idea is far from novel, it is still something I’ve wanted to do for a while: write a script that checks Twitter for new products. The more tech-savvy hypebeasts and sneakerheads are probably already familiar with “bots” which will poll websites or feeds for product reservations and/or the latest releases, giving them the upper hand against other users. Generally these bots are centric to mainstream companies (Nike, Adidas, Supreme to name a few), but I had my eyes set on a much smaller company: Outlier. Without getting into too much detail about the company itself, their sales are generally small batch/limited releases where items sell out in a matter of hours. So I did what any reasonable fanboy/programmer would do – I wrote a script to text me whenever there are new products or restocks announced on Twitter.
I’ve been playing around with Python recently (mostly data analysis) which makes it my go-to choice for messing around however, there is also a more practical reason to using Python which I will touch on later. With that being said, my Python is by no means perfect so any takeaways should be limited to ideas.
The Services
The first step in setting up this script is making sure we have access to one of Twitter’s APIs. I am using the REST API for this project however, the streaming API could also work. When you’re ready to start you can head over to the app page and create a new application for this script. Once you have done so you’ll have your keys and access tokens needed to use the API in your script.

The Twitter app page (I wonder what that application is for?)
The next step, which a normal person might replace with some sort of email notification, is to set up a Twilio account so that your program can send texts. Once you’ve signed up and verified your phone number you’ll have access to your authentication information and Twilio number (more info here).
The Detour
Now between these two services there’s a lot of sensitive information you wouldn’t want other people to see and it can be a pain to maintain a hardcoded credentials list in your program. Enter YAML and PyYAML, which I had never heard of until I started looking for information on Python config files (and also realized Sublime Text didn’t have pretty formatting for JSON). I whipped up my first YAML file and added all of the service credentials:
All you have to do is replace the “your…” text with your information (no quotes needed) and save!
Next we can go ahead and configure all of our services using our YAML file:
And we’re set, no more worrying about our exposed credentials (or phone number).
The Idea
So what exactly is the goal here? It isn’t to instantly buy the latest drops without any human intervention, instead we’re just trying to get a leg up on restock notifications and new products before normal people who don’t monitor the Outlier Twitter feed 24/7. After poking around for a bit it became clear that there was only one “type” of link we were interested in, which are the shop links. These links take the form of “http://shop.outlier.cc/shop/retail/product-name-here” however, between mention of their plans to switch to a .nyc domain (which is already up), and me being untrusting of future URL forms, I decided to just stick to searching for links which contained “shop.outlier”. The better way to have done this would be to create a domain crawler that would search for any new product pages on the website itself however, that is not the point of this project.
So now that we know what we’re looking for, how do we go about identifying if the link is to a new product, a restock, or just a promotional post they decide to send out? A new product would probably arrive with a link that hadn’t been used before, and therefore would not be on their feed history (the Twitter search API also has a few limitations in terms of history but enough that we’d probably still be interested in a reused link that was outside of this scope). A restock would use an existing link and probably have some mention of restocking or new stock in the tweet itself. A promotional post would probably just have an existing product link. Using this logic we can finally build our script.
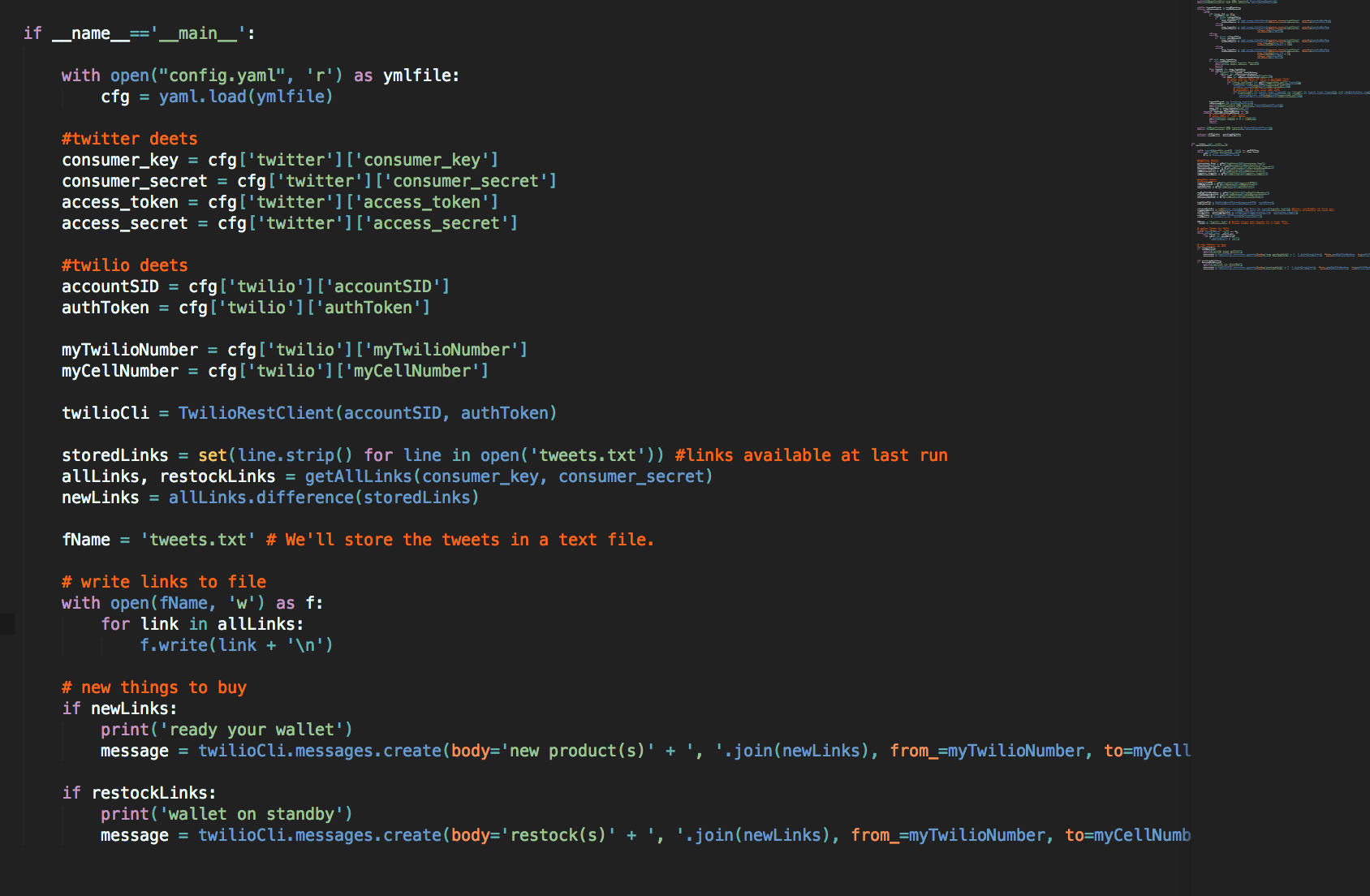
The Program
I wasn’t too familiar with the Twitter API when I first started this project and became very familiar with their rate limit exceeded warnings. I found a very helpful post, which explained how to better use its feature to crawl larger data sets. Taking a look at the example in the post, the JSON object that gets returned with each tweet contains a huge amount of data:
{"contributors": null, "truncated": false, "text": "RT @OutlierOnAir: 278: Davis Smith Interview \u2013 Adventure for Good https://t.co/FXkrm6Sntk #Outlier #Podcast #Entrepreneur https://t.co/o4z2\u2026", "is_quote_status": false, "in_reply_to_status_id": null, "in_reply_to_user_id": null, "id": 752174716668944385, "favorite_count": 0, "source": "<a href=\"https://roundteam.co\" rel=\"nofollow\">RoundTeam</a>", "retweeted": false, "coordinates": null, "entities": {"symbols": [], "media": [{"source_user_id": 913993326, "source_status_id_str": "752173796333875200", "expanded_url": "http://twitter.com/OutlierOnAir/status/752173796333875200/photo/1", "display_url": "pic.twitter.com/o4z2cLP9bS", "source_status_id": 752173796333875200, "media_url_https": "https://pbs.twimg.com/media/CnBCFHOXYAA65BB.jpg", "source_user_id_str": "913993326", "url": "https://t.co/o4z2cLP9bS", "id_str": "752173793376952320", "sizes": {"large": {"h": 392, "w": 354, "resize": "fit"}, "small": {"h": 392, "w": 354, "resize": "fit"}, "medium": {"h": 392, "w": 354, "resize": "fit"}, "thumb": {"h": 150, "w": 150, "resize": "crop"}}, "indices": [122, 140], "type": "photo", "id": 752173793376952320, "media_url": "http://pbs.twimg.com/media/CnBCFHOXYAA65BB.jpg"}], "hashtags": [{"indices": [90, 98], "text": "Outlier"}, {"indices": [99, 107], "text": "Podcast"}, {"indices": [108, 121], "text": "Entrepreneur"}], "user_mentions": [{"indices": [3, 16], "screen_name": "OutlierOnAir", "id": 913993326, "name": "Outlier On Air", "id_str": "913993326"}], "urls": [{"indices": [66, 89], "url": "https://t.co/FXkrm6Sntk", "expanded_url": "http://bit.ly/1SqN9P5", "display_url": "bit.ly/1SqN9P5"}]}, "in_reply_to_screen_name": null, "id_str": "752174716668944385", "retweet_count": 2, "metadata": {"iso_language_code": "en", "result_type": "recent"}, "favorited": false, "retweeted_status": {"contributors": null, "truncated": false, "text": "278: Davis Smith Interview \u2013 Adventure for Good https://t.co/FXkrm6Sntk #Outlier #Podcast #Entrepreneur https://t.co/o4z2cLP9bS", "is_quote_status": false, "in_reply_to_status_id": null, "in_reply_to_user_id": null, "id": 752173796333875200, "favorite_count": 0, "entities": {"symbols": [], "media": [{"expanded_url": "http://twitter.com/OutlierOnAir/status/752173796333875200/photo/1", "display_url": "pic.twitter.com/o4z2cLP9bS", "url": "https://t.co/o4z2cLP9bS", "media_url_https": "https://pbs.twimg.com/media/CnBCFHOXYAA65BB.jpg", "id_str": "752173793376952320", "sizes": {"large": {"h": 392, "w": 354, "resize": "fit"}, "small": {"h": 392, "w": 354, "resize": "fit"}, "medium": {"h": 392, "w": 354, "resize": "fit"}, "thumb": {"h": 150, "w": 150, "resize": "crop"}}, "indices": [104, 127], "type": "photo", "id": 752173793376952320, "media_url": "http://pbs.twimg.com/media/CnBCFHOXYAA65BB.jpg"}], "hashtags": [{"indices": [72, 80], "text": "Outlier"}, {"indices": [81, 89], "text": "Podcast"}, {"indices": [90, 103], "text": "Entrepreneur"}], "user_mentions": [], "urls": [{"indices": [48, 71], "url": "https://t.co/FXkrm6Sntk", "expanded_url": "http://bit.ly/1SqN9P5", "display_url": "bit.ly/1SqN9P5"}]}, "retweeted": false, "coordinates": null, "source": "<a href=\"http://meetedgar.com\" rel=\"nofollow\">Meet Edgar</a>", "in_reply_to_screen_name": null, "id_str": "752173796333875200", "retweet_count": 2, "metadata": {"iso_language_code": "en", "result_type": "recent"}, "favorited": false, "user": {"follow_request_sent": null, "has_extended_profile": false, "profile_use_background_image": true, "id": 913993326, "verified": false, "profile_text_color": "666666", "profile_image_url_https": "https://pbs.twimg.com/profile_images/551626141539115008/bdVoRLMQ_normal.jpeg", "profile_sidebar_fill_color": "252429", "entities": {"url": {"urls": [{"indices": [0, 23], "url": "https://t.co/OC8w8YgqJt", "expanded_url": "http://OutlierMagazine.co", "display_url": "OutlierMagazine.co"}]}, "description": {"urls": []}}, "followers_count": 5971, "protected": false, "location": "Utah", "default_profile_image": false, "id_str": "913993326", "lang": "en", "utc_offset": -21600, "statuses_count": 8680, "description": "Digital magazine & podcast featuring startups & entrepreneurs making an impact in their industries. New episodes Mon-Fri w/ @_EverGonzalez #OutlierOnAir.", "friends_count": 4545, "profile_background_image_url_https": "https://abs.twimg.com/images/themes/theme9/bg.gif", "profile_link_color": "2FC2EF", "profile_image_url": "http://pbs.twimg.com/profile_images/551626141539115008/bdVoRLMQ_normal.jpeg", "following": null, "geo_enabled": false, "profile_background_color": "1A1B1F", "profile_banner_url": "https://pbs.twimg.com/profile_banners/913993326/1467441792", "profile_background_image_url": "http://abs.twimg.com/images/themes/theme9/bg.gif", "screen_name": "OutlierOnAir", "is_translation_enabled": false, "profile_background_tile": false, "favourites_count": 1801, "name": "Outlier On Air", "notifications": null, "url": "https://t.co/OC8w8YgqJt", "created_at": "Tue Oct 30 06:08:28 +0000 2012", "contributors_enabled": false, "time_zone": "Mountain Time (US & Canada)", "profile_sidebar_border_color": "181A1E", "default_profile": false, "is_translator": false, "listed_count": 445}, "geo": null, "in_reply_to_user_id_str": null, "possibly_sensitive": false, "lang": "en", "created_at": "Sun Jul 10 16:13:02 +0000 2016", "in_reply_to_status_id_str": null, "place": null}, "user": {"follow_request_sent": null, "has_extended_profile": true, "profile_use_background_image": true, "id": 55207986, "verified": false, "profile_text_color": "333333", "profile_image_url_https": "https://pbs.twimg.com/profile_images/636181078147903488/svtegGO0_normal.jpg", "profile_sidebar_fill_color": "DDFFCC", "entities": {"url": {"urls": [{"indices": [0, 23], "url": "https://t.co/TTnxc41eg9", "expanded_url": "http://koffee-o-matic.com/", "display_url": "koffee-o-matic.com"}]}, "description": {"urls": []}}, "followers_count": 26778, "protected": false, "location": "Parkesburg, PA", "default_profile_image": false, "id_str": "55207986", "lang": "en", "utc_offset": -14400, "statuses_count": 101343, "description": "Entrepreneur, Marketer, and Blogger ~ Proud Dad, Grandpa, Coffee Junkie, Whovian, Bacon Evangelist ~ Focused on #DigitalMarketing and #SocialMedia", "friends_count": 24072, "profile_background_image_url_https": "https://pbs.twimg.com/profile_background_images/614658919596625920/Lbf_XMJG.jpg", "profile_link_color": "9C77B8", "profile_image_url": "http://pbs.twimg.com/profile_images/636181078147903488/svtegGO0_normal.jpg", "following": null, "geo_enabled": true, "profile_background_color": "9C77B8", "profile_banner_url": "https://pbs.twimg.com/profile_banners/55207986/1442198733", "profile_background_image_url": "http://pbs.twimg.com/profile_background_images/614658919596625920/Lbf_XMJG.jpg", "screen_name": "TimothyAlex", "is_translation_enabled": false, "profile_background_tile": false, "favourites_count": 9861, "name": "Tim Alexander", "notifications": null, "url": "https://t.co/TTnxc41eg9", "created_at": "Thu Jul 09 11:22:16 +0000 2009", "contributors_enabled": false, "time_zone": "Eastern Time (US & Canada)", "profile_sidebar_border_color": "FFFFFF", "default_profile": false, "is_translator": false, "listed_count": 3673}, "geo": null, "in_reply_to_user_id_str": null, "possibly_sensitive": false, "lang": "en", "created_at": "Sun Jul 10 16:16:41 +0000 2016", "in_reply_to_status_id_str": null, "place": null}
While normally that’s a nice feature to have, we’re only interested in a few fields: extended_url, text, and created_at. I am, unfortunately, not super familiar with the performance of datatypes on Python, but stackoverflow seems to tell me sets are very quick and would be useful for storing unique URLS. So, with these changes in mind we can create a function that will return a set of all links and a set of links that mention restocks that are less than two days old (before all of the diehard fans clear out stock again):
Once we have a list of all of the shop links, and a separate list of restock links, we can do a simple left join to see what the new links are since the last time the program was run:
Now we’re ready to send out our text notifications (because we need to know about these drops ASAP). Two calls to Twilio’s message service send out comma-separated links directly to your phone for you to review (you just have to hope they don’t launch too many products at once). And there you have it, your very own text notification program to alert you to all the sick new merch from Outlier (that appear on Twitter before their email list). Hopefully this will give you some ideas of how you can programmatically exploit Twitter for your personal gain (and financial loss).

The more astute reader may be wondering “so what?”, “what is this event crawler that clearly is not mentioned in this post?”, “how often to I have to hit ⌘-b in Sublime?”, or how does this script actually help me if I still have to run it manually as often as possible. All strong questions, and questions that will be answered soon in a more comprehensive write-up. Stay tuned!
See the full script on Github